


Deep Dive: Mixture of Experts Explained
Deep Dive: Mixture of Experts Explained
How MoE LLMs differ from Dense LLMs?

Earlier this week, I talked about Databricks release of DBRX LLM and its implication on the enterprise landscape. DBRX also happens to be a Master of Experts (MoE) LLM built on MegaBlocks research and this type of LLM architecture has been gaining traction lately so I thought to publish a deeper dive into MoEs.
Let me know via comments if this deep dive has been helpful to you! 🙏
Overview
Master of Experts (MoE) is a novel architecture for large language models (LLMs) that aims to improve their efficiency, scalability, and performance. This approach involves decomposing the model into multiple smaller expert models, each specializing in a specific task or domain.
The MoE architecture consists of two main components:
1. Experts: These are the individual models or sub-networks that are trained to become specialists in specific areas. For example, there could be experts for natural language understanding, question answering, mathematical reasoning, and so on.
2. Router (or Gating Network): The router is a component responsible for selectively activating the relevant experts based on the input data. It learns to route the input to the most appropriate experts, ensuring that only a subset of experts is used for a given input, rather than the entire model.
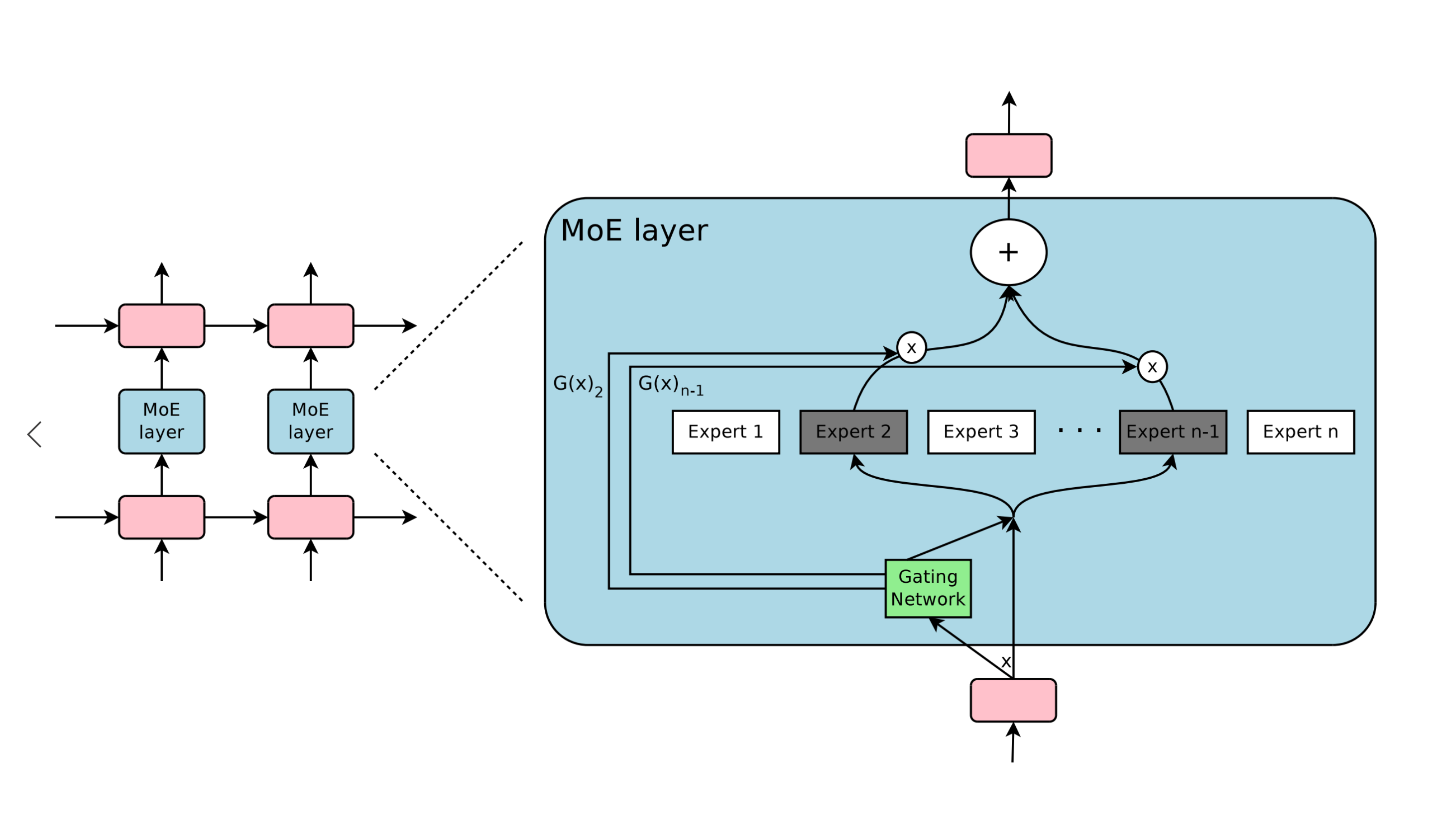
MoE Workflow
The workflow of an MoE LLM typically involves the following steps:
The input data (e.g., a text sequence) is fed into the router (or gating network).
The router analyzes the input and determines which experts are most relevant for processing it.
The router activates (or "routes") the input to the selected experts, while deactivating the irrelevant experts.
The activated experts process the input independently and in parallel.
The outputs from the activated experts are combined (e.g., through a weighted sum or other ensemble methods) to produce the final output.
Advantages of MoE Architecture
The MoE architecture offers several advantages:
Improved efficiency: By selectively activating only the relevant experts, MoE models can be more computationally efficient than traditional monolithic models, especially for tasks that require specialized knowledge.
Scalability: As the model size grows, it becomes easier to add new experts without significantly increasing the overall computational cost, enabling better scalability.
Specialization: Experts can specialize in specific domains or tasks, potentially leading to better performance compared to a single, generalized model.
Modularity: The modular nature of MoE models allows for easier maintenance, updating, and fine-tuning of individual experts without affecting the entire model.
How MoE differs from Dense LLMs
Here are some key ways Mixture of Experts (MoE) models differ from dense large language models (LLMs).

Summary
In summary, while dense LLMs have all parameters engaged uniformly, MoE architectures enable conditional sparse computation, better scaling, specialization of components, and more efficient inference - key attributes that could allow advancing AI capabilities at reduced costs.
However, MoE models also come with challenges, such as the need for an effective routing mechanism, potential communication overhead between experts, and the complexity of training and ensembling multiple expert models.
Top MoE Papers
"Outrageously Large Neural Networks: The Sparse-Weight Back-Propagation Algorithm" (1991) by Geoffrey Hinton - The seminal paper that introduced the MoE concept.
“Learning Factored Representations in a Deep Mixture of Experts” (2013) - MoE were applied to deep learning
"GShard: Scaling Giant Language Models with Conditional Computation and Automatic Sharding" (2021) - Describes Google's GShard model that applied MoEs to sparse transformer activations.
"Switch Transformers: Scaling to Trillion Parameter Models" (2021) - Introduces Switch Transformers, Google's approach to address training instabilities in large MoE models.
"GLaM: Efficient Scaling of Language Models" (2022) - Describes Google's GLaM model that scales language models efficiently using MoEs.
“MegaBlocks: Efficient Sparse Training with Mixture-of-Experts“ (2022) - Databricks DBRX is built on MegaBlocks research
Community: Share your updates with other readers by telling us what you are working on here.
Thank you for your continued support of the newsletter and the growth so far. Did you find this issue valuable? If so, you can also hit the like ❤️ button at the bottom of this email to help support me or share 🔄 this with a friend. It really helps!